Using the NOMAD API
In this tutorial you are going to learn how to:
Let’s get started!
[1]:
# imports
from madas.apis.NOMAD_web_API import get_atoms
from madas.utils import resolve_nested_dict
import matplotlib.pyplot as plt
from scipy.constants import electron_volt
Writing a NOMAD query
To download data, we have to query the NOMAD service. To do so, you can use the NOMAD documentation, or the GUI copy the query over. In this example, we query for bulk GaP structures calculated with DFT using a hybrid functional.
[2]:
query = {
"results.material.structural_type:any": [
"bulk"
],
"results.method.simulation.dft.xc_functional_type:any": [
"hybrid"
],
"datasets.dataset_name:any": [
"reproducibility_of_HSE"
],
"results.material.elements:all": [
"Ga",
"P"
],
"results.properties.available_properties:all": [
"dos_electronic"
]
}
The NOMAD API requires that we specify which data is requested. For our initial query, we want all data, therefore we define:
[3]:
required = {"required" : "*"}
Querying the NOMAD API
To start quering NOMAD, we first import and initialize an API object:
[4]:
from madas.apis.NOMAD_web_API import API
api = API()
In order to reduce traffic, we just download a single entry:
[5]:
full_archives = api.get_calculations_by_search(query, # defined above
required=required, # defined above
max_entries=1) # one entry only
Found 5 entries
Possibly not all entries discovered due to max_entries limit
Downloading 1 entries
Finished download.
[6]:
len(full_archives)
[6]:
1
Analyzing the data
We can inspect some properties of the Material object that we just created:
[7]:
example_material = full_archives[0]
print(example_material)
Material(mid = FIUqPOMua13ySJrnOynrNDnT5Xge, data = {'archive'}, properties = set())
In the data attribute of the material we now find the full NOMAD archive entry. We can explore its contents to automatically extract the data we need. The atomic structure has been parsed already by default and can be visualized:
[8]:
from madas.plotting import plot_material
plot_material(example_material, repeat=[1,1,1], show_unit_cell=2)
To build the automatic parsers of the NOMAD Archive entries, we can inspect the contents of the Archive. For this example, we want to obtain the total energy of the material. To do so, we need to parse the workflow section of the Archive:
[9]:
example_material.data['archive'].keys()
[9]:
dict_keys(['processing_logs', 'run', 'workflow', 'metadata', 'results', 'm_ref_archives'])
We can use a MADAS tool to find the path to the required quantity in this dictionary:
[10]:
from madas.utils import print_key_paths
[11]:
print_key_paths("calculation_result_ref", example_material.data["archive"])
/workflow/0/calculation_result_ref
This calculation contains one reference to result, i.e. the final calculation of a workflow that is used to obtain physical properties. We can investigate which calculation this is:
[12]:
resolve_nested_dict(example_material.data["archive"], "workflow/0/calculation_result_ref")
[12]:
'/run/0/calculation/0'
Next we figure out which how to parse the total energy that was computed in this calculation.
[13]:
print_key_paths("energy", example_material.data["archive"])
/run/0/calculation/0/energy
/run/0/calculation/0/scf_iteration/0/energy
/run/0/calculation/0/scf_iteration/1/energy
/run/0/calculation/0/scf_iteration/2/energy
/run/0/calculation/0/scf_iteration/3/energy
/run/0/calculation/0/scf_iteration/4/energy
/run/0/calculation/0/scf_iteration/5/energy
/run/0/calculation/0/scf_iteration/6/energy
/run/0/calculation/0/scf_iteration/7/energy
/run/0/calculation/0/scf_iteration/8/energy
/run/0/calculation/0/scf_iteration/9/energy
/run/0/calculation/0/scf_iteration/10/energy
/run/0/calculation/0/scf_iteration/11/energy
/run/0/calculation/0/scf_iteration/12/energy
/run/0/calculation/0/scf_iteration/13/energy
/run/0/calculation/0/scf_iteration/14/energy
/run/0/calculation/0/scf_iteration/15/energy
/run/0/calculation/0/scf_iteration/16/energy
/run/0/calculation/0/scf_iteration/17/energy
/run/0/calculation/0/scf_iteration/18/energy
/run/0/calculation/0/scf_iteration/19/energy
/run/0/calculation/0/scf_iteration/20/energy
/run/0/calculation/0/scf_iteration/21/energy
/run/0/calculation/0/scf_iteration/22/energy
/run/0/calculation/0/scf_iteration/23/energy
/run/0/calculation/0/scf_iteration/24/energy
The first entry corresponds to the result, the others show the energies at the respective scf iterations of the DFT calculation. Here we are only interested in the results. We print the respective values:
[14]:
resolve_nested_dict(example_material.data['archive'], "run/0/calculation/0/energy")
[14]:
{'fermi': 5.387333367436472e-19,
'highest_occupied': 5.2360734575754e-19,
'lowest_unoccupied': 8.924444286706798e-19,
'total': {'value': -1.9285848977220246e-18},
'free': {'value': -1.9285848977220246e-18},
'total_t0': {'value': -0.0}}
From this, we can resolve the total energy value (in Joule):
[15]:
resolve_nested_dict(example_material.data['archive'], "run/0/calculation/0/energy/total/value")
[15]:
-1.9285848977220246e-18
We can automatize this process by writing a small function:
[16]:
def get_total_energy(archive: dict) -> float:
energy_ref = resolve_nested_dict(archive, 'archive/workflow/0/calculation_result_ref')
energy_ref = f'archive/{energy_ref.strip("/")}/energy/total/value'
energy = resolve_nested_dict(archive, energy_ref)
return energy / electron_volt
Using this function, we can directly access the total energy (in eV).
[17]:
get_total_energy(full_archives[0].data)
[17]:
-12.037280139999998
Automatic processing
We can now automatize what we did before. To do so, we define a dictionary processing, which contains as keys the name of the quantity we want to obtain, and the function to extract them from the NOMAD data as values:
[18]:
processing = {
'atoms' : get_atoms, # 'atoms' is predefined here and is expected to return an ase Atoms object
'energy_total' : get_total_energy,
}
Since we don’t need all parts of the NOMAD data anymore, we can adapt the required dictionary:
[19]:
required_processed = {
"required" : {
"workflow" : "*", # contains which calculation has the optimized total energy
"run" : "*", # contains the total energy value
"results" : "*" # contails the atomic structure
}
}
Then we create a new API object, to download and process only the data we need:
[20]:
api_modified = API(processing=processing)
We can run the query:
[21]:
materials = api_modified.get_calculations_by_search(query, required=required_processed)
for material in materials:
print(material)
Found 5 entries
Finished download.
Material(mid = FIUqPOMua13ySJrnOynrNDnT5Xge, data = {'energy_total'}, properties = set())
Material(mid = MDy6puRcMwjin26GFGaIoWuyTZw5, data = {'energy_total'}, properties = set())
Material(mid = MawJNfJFAVzVaZkOfsTJnWws0wmp, data = {'energy_total'}, properties = set())
Material(mid = 3WER3GH6byHNIUQTOWxNf_vhlA28, data = {'energy_total'}, properties = set())
Material(mid = l4YBhD_KzKalkX8cvDJ9oTIHSgZg, data = {'energy_total'}, properties = set())
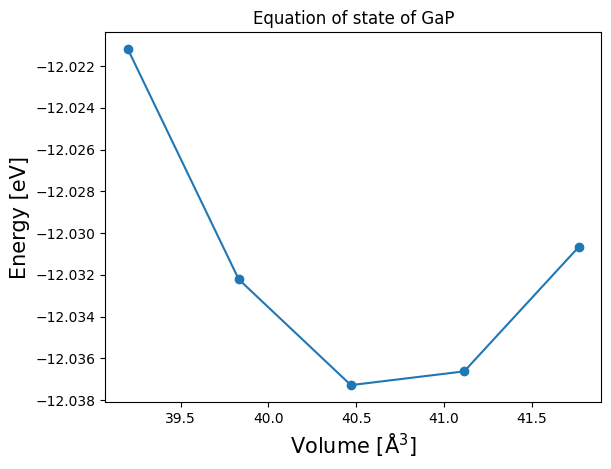
From the available data, we can plot the equation of state (EOS) as a function of the unit cell volume:
[22]:
volumes = []
total_energies = []
for mat in materials:
volumes.append(mat.atoms.get_volume())
total_energies.append(mat.data['energy_total'])
volumes, total_energies = zip(*sorted(zip(volumes, total_energies), key=lambda x: x[0]))
plt.plot(volumes, total_energies, "o-")
plt.xlabel("Volume [Å$^3$]", fontsize=15)
plt.ylabel("Energy [eV]", fontsize=15)
plt.title("Equation of state of GaP")
plt.show()